Node JS ilə web scraping (başqa saytlardan məlumatların götürülməsi)
Veb proqramçıların daimi olaraq scraping etmə ehtiyacı olur. Bu vebin ayrılmaz hissəsindən biridir desəm yalan olmaz. Məqaləni Fuad Rüstəmzadənin Medium bloqunda gördüm və faydalı olduğu üçün icazəsi ilə paylaşıram.
Scraping-i əksər proqramlaşdırma dilləri ilə etmək mümkündür. Lakin bu məqalədə Fuad JavaScript proqramlaşdırma dili istifadə edərək, Node.js ilə ona verilən tapşırığı həll edib. Başlayaq:
İlk işim sırf bununla bağlı idi. Bu barədə heç nə bilməsəm də, işi boynuma götürdüm. Biraz internetdə araşdırandan sonra, gördüm ki, web scraping-i əsasən Python ilə edirlər. Python-dan bir az anlayışım var idi amma syntax-ı yada salmaq, sonra bu dilə aid alətləri öyrənmək çox vaxtımı alacaqdı. Mən isə tapşırığı vaxtında çatdırmalı idim və buna görə də Node JS ilə işi necə görməli olduğumu öyrənməli idim.
Junior-un ilk nəticəsi – heç vaxt kömək istəməkdən utanmayın. Heç vaxt üz-üzə görmədiyim, dostumun dostu olan və Node JS üzrə proqramçı işləməyən developer tanışımdan kömək istədim. Kimin nə ilə kömək edə biləcəyi həqiqətən bilinmir. O mənə dedi ki, Cheerio haqqında maraqlanım, çox guman ki, iş bu alətlə görüləcək. Cheerio-nun adını ilk dəfə eşitməyimə baxmayaraq, GitHub səhifələrini açanda çox sevinmişdim. Bu ki jQuery-dir! Nə isə, uzatmadan, Node JS ilə scrape etməyin, pythondan çox da geri qalmadığını yavaş-yavaş göstərim.
Proyektə hazırlıq və dependency-lərin əlavəsi
Terminalı açırıq, istədiyimiz directory-a keçirik və bu proyektə başlayırıq.
Daha sonra dependency-ləri yazmaq lazımdır. Axtarışlarım headless brauzerlərə qədər davam etmişdi. Hətta ilk dəfə nightmare-dən istifadə etmişdim.
Junior-un ikinci nəticəsi – lazım olmadan işini qəlizləşdirmə.
Cəmi üç packet və işə başlamaq olar. Bunun üçün bir sayt seçək. Məsələn, Vikipedia-nın ana səhifəsində günün əsəri hissəsini scrape edən app yazaq.
İlk növbədə lazım olan paketləri require edək.

Paketlər əlavə olunandan sonra isə funksiyanı yazmağa başlamaq olar. İlk növbədə url-i constant ilə qeyd edək ki, gələcəkdə request edərkən onu istənilən başqa url ilə rahat əvəz etmək olsun. Bizim kiçik app-ımızda request paketi lazım olan işi görür və heç bir headless brauzerə ehtiyac qalmır. Request-lə url-ə keçid alırıq, mütləq error-ların olmadığını yoxlayırıq və əgər statusCode 200-ə bərabərdirsə, yəni bağlantı lazımi formadadırsa, cheerio ilə lazım olan tag-ı tapırıq. Bunun üçün əvvəlcə Chrome Developer Tools-u həmin səhifədə açıb, bizə lazım olan tag-ı tapırıq.
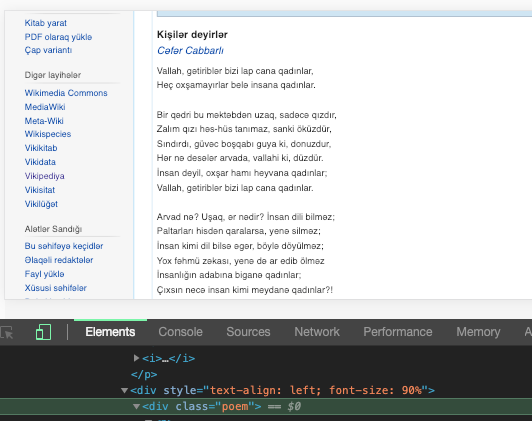
Bizə poem class-ı olan div və o divin içindəki p- tag-ı lazımdır.
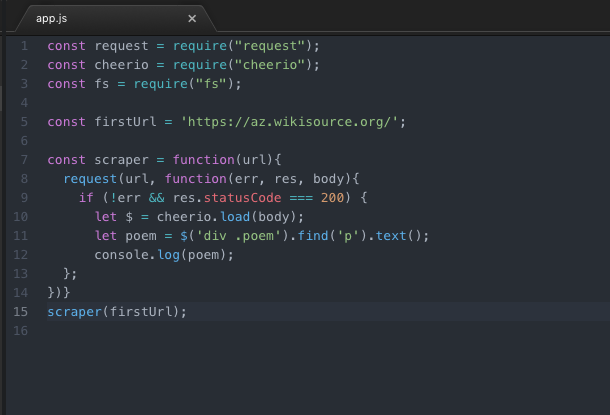
Məlumatların fayla yazılması
Gördüyünüz kimi cheerio jQuery kimidir və asan istifadəsi var. Python-da olan Beautiful Soup paketi də buna bənzər formada işləyir. Faylın sonunda isə mənim kimi diqqətsiz deyilsizsə, funksiyanı çağırmağı unutmayın. Yoxsa console-da 5 dəqiqə vaxtınız ölməyəcək. İndi isə yüklənən mətni console-a deyil, fayla yazaq.
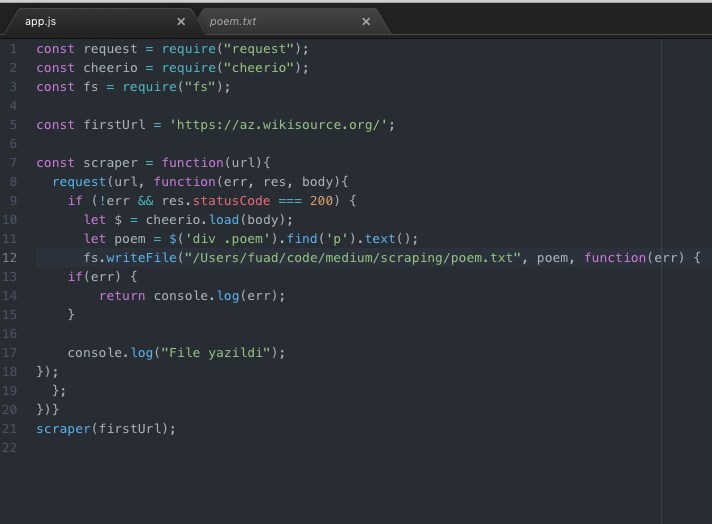
Node JS-in öz tərkibində olan fs modulu ilə bunu edə bilərik. Davamı qeyri-praktiki tərəfləridir. Kimə maraqlı olmasa, oxumaya bilər.Təbii ki, işdən mənə tapşırılan app bundan qat-qat böyük idi amma mahiyyət etibarı ilə fərqlənmirdi. Bura MySQL-i də inteqrasiya etsək, həmin şey alınacaq. O zaman həm scraping, həm də MySQL mənim üçün yeni idi və ümumiyyətlə coding barədə ilk real tapşırıq yerinə yetirirdim. İlk tapşırıq həll olandan sonra anladığım məqamlar bunlar oldu:
- Soruşmaqdan çəkinməməliyik
- Öz işimizi özümüz qəlizləşdirməməliyik
- İşdən qorxmaq əvəzinə, ona irəliləməyə vasitə kimi baxmalıyıq
Dostlar, yeni başlayan proqramçılara daha çox fayda verə bilmək üçün, siz də maraqlı məqalələrinizi mənə yazaraq göndərin, saytda paylaşaq.



Write a Comment